结题报告
Slides
( 悬停于幻灯片左下角以导航 or 全屏观看 )
目录
项目简介
IOSYS 主要致力于开发出 “更强大的文件系统 Agent”。我们希望通过深度语义理解、图状文件组织范式以及全面的语义信息集成,构建一个以自然语言为核心交互界面的智能文件管理系统。报告将详细介绍项目的背景动机、核心创新点、系统总体架构、各功能模块(包括 Agent、文件系统、文件解析器、RAG 核心、Web UI 及 A2A 服务器)的设计与实现、项目管理实践以及最终成果。IOSYS 不仅继承并优化了往届项目的技术积累,更在体系结构、交互范式和未来可扩展性上做出了有价值的探索,例如引入知识图谱技术和前瞻性的 Agent2Agent (A2A) 协议,为下一代智能操作系统(AIOS)的发展趋势提供了实践性的参考。
项目统计:
- 6600+ Python 代码行
- 1800+ Vue 代码行
- 440+ TypeScript 代码行
- 570+ 提交数
1. 引言
1.1. 项目背景与动机
近年来,将 LLM 与操作系统结合,以期实现更智能、更自然的人机交互,已成为一个显著的技术趋势,被概括为 AIOS 的概念。往年也有不少同学开发项目, 然而, 他们或多或少都存在一定的局限性:
- My-Glow (2023): 该项目在分布式框架和鲁棒性监控上表现出色,但其文件标记仍依赖传统方法,未能充分利用 LLM 的深度语义理解能力。我们引入了 LlamaIndex 等现代框架进行优化。
- ArkFS (2024): ArkFS 在多模态向量化和二分图映射方面进行了有益探索,但其图结构相对简化,未能完全展现文件间复杂的语义关联。我们认为引入 知识图谱 技术将是其关键的演进方向。
- vivo50 (2024): 该项目实现了优秀的自然语言/语音交互和任务序列转换,但受限于传统的 RAG(检索增强生成)架构,其 Agent 的主动性和能力边界明显。我们采用 Tool Call(工具调用) 的动作执行机制来尝试突破此限制的核心。
更深层次地,为何此类系统尚未普及? 一个可能的原因在于, 当前多数系统提供的功能(如“删除电脑中一张包含树的图片”)虽然新颖,但并未触及用户文件管理的核心痛点。因此,IOSYS 项目的根本目标是超越简单的语义查询,构建一个真正能提升文件组织、检索和操作效率的强大 Agent。
1.2. 项目目标
IOSYS 的核心目标包括:
- 实现基于自然语言的核心文件操作:让自然语言成为与文件系统交互的一级界面,无缝执行增删查改等任务。
- 构建图状文件组织新范式:以图的形式重新组织和呈现文件,打破传统目录树的层级限制。
- 提升操作效率:通过深度语义理解和优化的系统架构,尝试提升各类文件管理的效率。
1.3. 核心创新点
为实现上述目标,IOSYS 在以下三个方面进行了创新:
- 深度语义理解驱动的文件管理:系统不仅仅依赖文件名或元数据等浅层信息,而是深入文件内容,实现真正的语义级理解,使 agent 能通过复杂的自然语言指令进行精确、高效的文件管理。
- 图状文件组织范式:我们打破了目录、文件和嵌入文件(如 Word 文档中的图片)之间的界限,将它们统一为图中的节点。通过与 知识图谱 的结合,文件间的内在联系得以显式化、可视化,为用户提供了全新的文件组织与探索维度。
- 全面的语义信息集成:系统整合了包括文件元数据、文件间显式/隐式关系、用户交互历史在内的多维度信息,构建了更细粒度、更全面的数据视图,从而为 agent 的决策提供了更丰富的上下文。
2. 系统架构与实现
2.1. 总体架构
IOSYS 系统采用高度模块化的设计理念,整个系统由七个核心模块构成,如下图所示。各模块间几乎解耦,通过较为清晰的接口进行协作,保证了系统的高内聚、低耦合和可扩展性。

- 七大模块: Web UI、Backend、Agent、RAG Core (包含 Vector Indexing, Knowledge Graph, File Graph)、File System、File Parser、A2A Server。
2.2. 核心模块讲解
2.2.1. Agent 模块与交互协议
Agent 是用户交互的核心枢纽。其主要职责是:处理用户的自然语言请求,利用 LLM 进行意图理解和任务规划,并调用各种 Tools 来获取信息或执行具体操作。

工具调用 (Tool Call): 为了让 LLM 理解用户需求并解析出机器友好的信息, 我们采用了 Tool Call 机制,赋予 LLM 主动调用工具的能力。但注意, 全部的 Tool 都必须自己实现, 他们并不是由服务商提供的, 所谓的 Tool Call 机制是让 LLM 从我们自己设计的一系列 Tool 中选择一系列它认为为了完成任务所需要的工具。这使得 Agent 不仅能查询信息(如读取文件内容),还能执行动作(如创建目录、生成文档)。
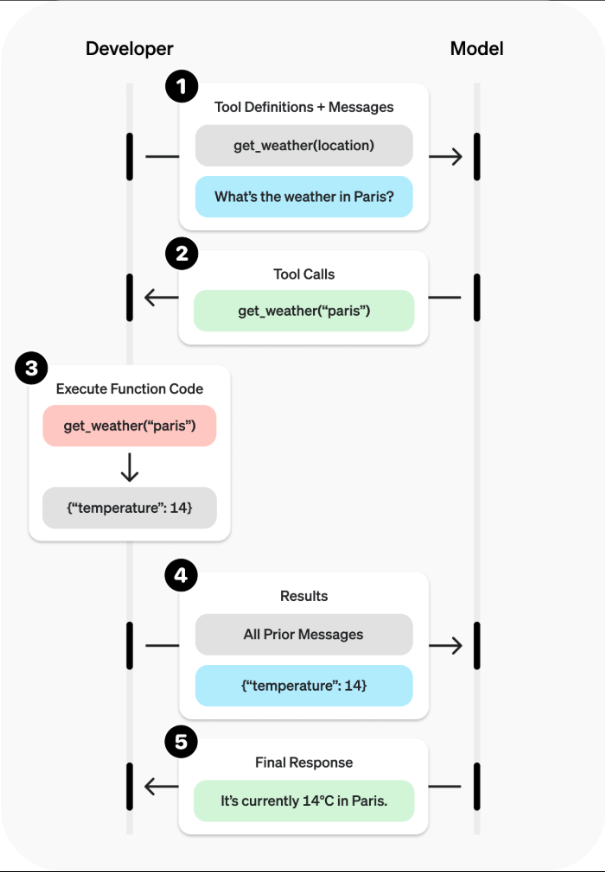
为了支持完成复杂任务, 例如 “请总结文件夹 A 下全部文件的内容,并将结果保存到文件 B”, 我们引入了类似思维链的多轮调用机制, 也即 agent 在执行完一轮任务后, 并不会立刻返回处理结果, 而是开启一轮新的思考, 结合先前已经完成的任务, 判断接下来一轮需要用到的 Tool, 如此循环, 直到解析出不再需要调用 Tool, 此时任务就真正地完成了。
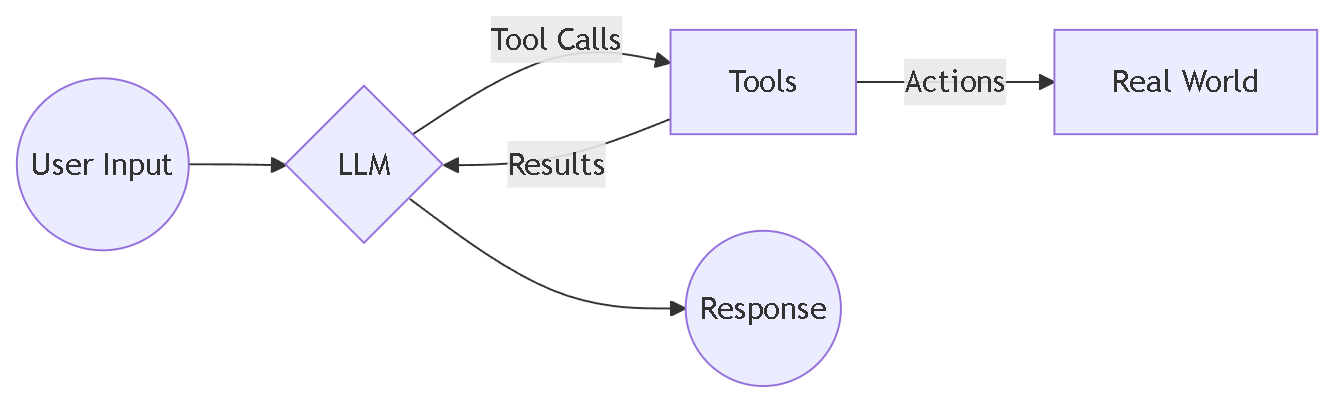
模型上下文协议 (MCP) 为了标准化工具的定义与调用,我们采用了业界广泛使用的 Model Context Protocol (MCP) 协议。该协议支持通过 JSON 格式的配置文件轻松启用或关闭特定外部工具,具有良好的通用性和可管理性。
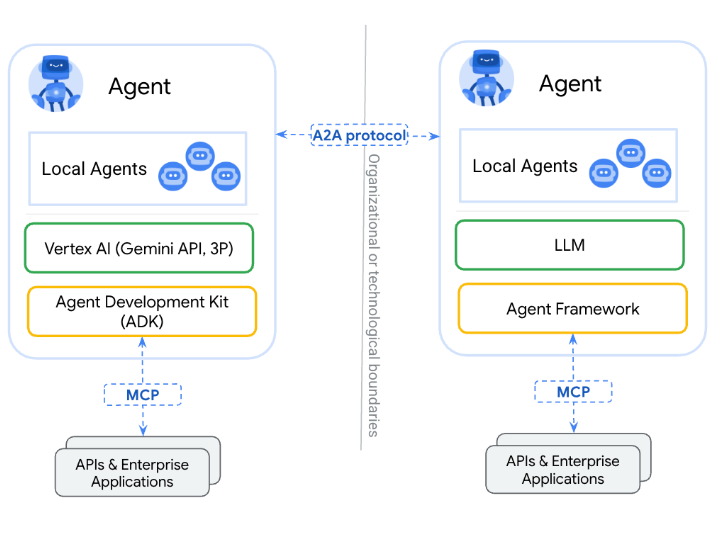
Agent2Agent (A2A) 协议 为了系统能够被进一步开发,我们集成了 Google 于 2025 年 4 月提出的 Agent2Agent (A2A) 协议。与 MCP 专注于“Agent 如何使用工具”不同,A2A 定义了“Agent 之间如何协作”。这为 IOSYS 在未来融入更广泛的 Agent 生态系统,实现跨 Agent 的任务协同,奠定了基础。
2.2.2. File System 模块以及分布式部署
File System 模块提供了一套统一的存储接口,原生支持元数据和创新的“嵌入文件”概念,并支持两种后端实现。
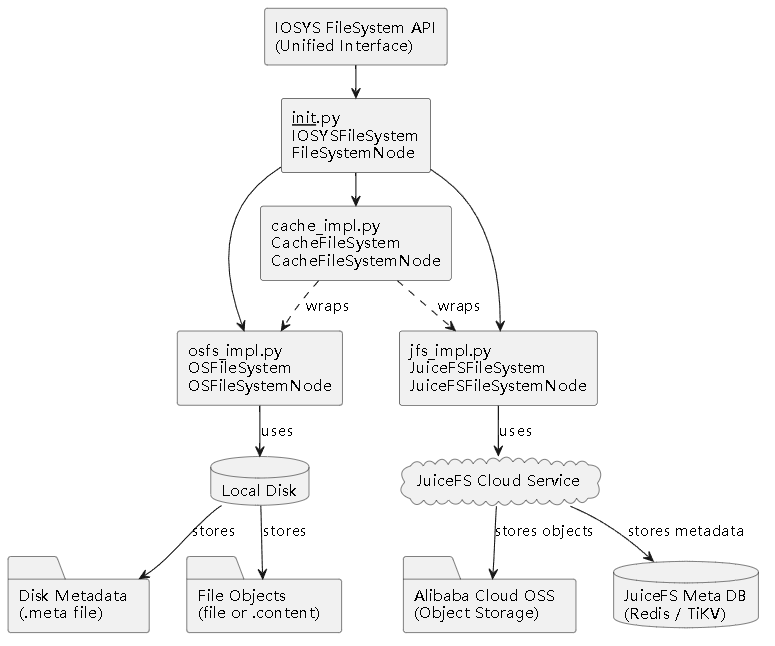
双重实现:
OSFS: 直接在本地进行操作的文件系统。也即数据存储在本地磁盘上.
JFS: 我们在 IOSYS 中对接了 JuiceFS 分布式文件系统。JuiceFS 是一款云原生存储解决方案,我们将其与阿里云 OSS 的结合,实现了系统的跨平台、高可用和易于二次开发的特性。部分效果如下:
“嵌入文件”概念: 我们通过抽象, 统一了文件与目录的定义, 也即
目录 = 文件 - 内容;文件 = 目录 + 内容. 例如将 Word 文档中内嵌的图片等资源视为源文件的子节点。这种设计使得所有文件资源,无论其形式,都享有一致的操作接口,极大地简化了上层逻辑。
2.2.3. File Parser 模块
该模块负责对多模态数据进行解析、文本化和概要生成,是连接原始文件和上层语义理解的桥梁。

核心功能:
- 文本化: 基于修改后的
markitdown,将各种格式的文件(包括不能直接读取的二进制等类型文件, 如 Word, PDF)转换为纯文本。 - 概要生成: 调用 LLM 对文本内容生成多层级的摘要。
- 嵌入文件提取: 识别并提取文件内嵌的非纯文本类型资源(如图片),为构建文件图提供依据, 也让文件能够被更加全面地解析, 不会丢失这些信息。
- 文本化: 基于修改后的
异步执行: 实际上, parser 是一个比较耗时的操作,因此我们设计了异步执行机制: 当一个文件被创建或者更新时, parser 任务会被放入队列中, 从而不会第一个被执行, 此时允许系统优先响应用户的即时请求,提升了系统的交互体验。
一个实际的例子如下:

2.2.4. RAG Core: 知识图谱与向量索引
RAG (Retrieval-Augmented Generation) 是系统实现深度语义理解的关键,在 IOSYS 中, 它主要由知识图谱和向量索引两部分构成。
知识图谱 (Knowledge Graph):
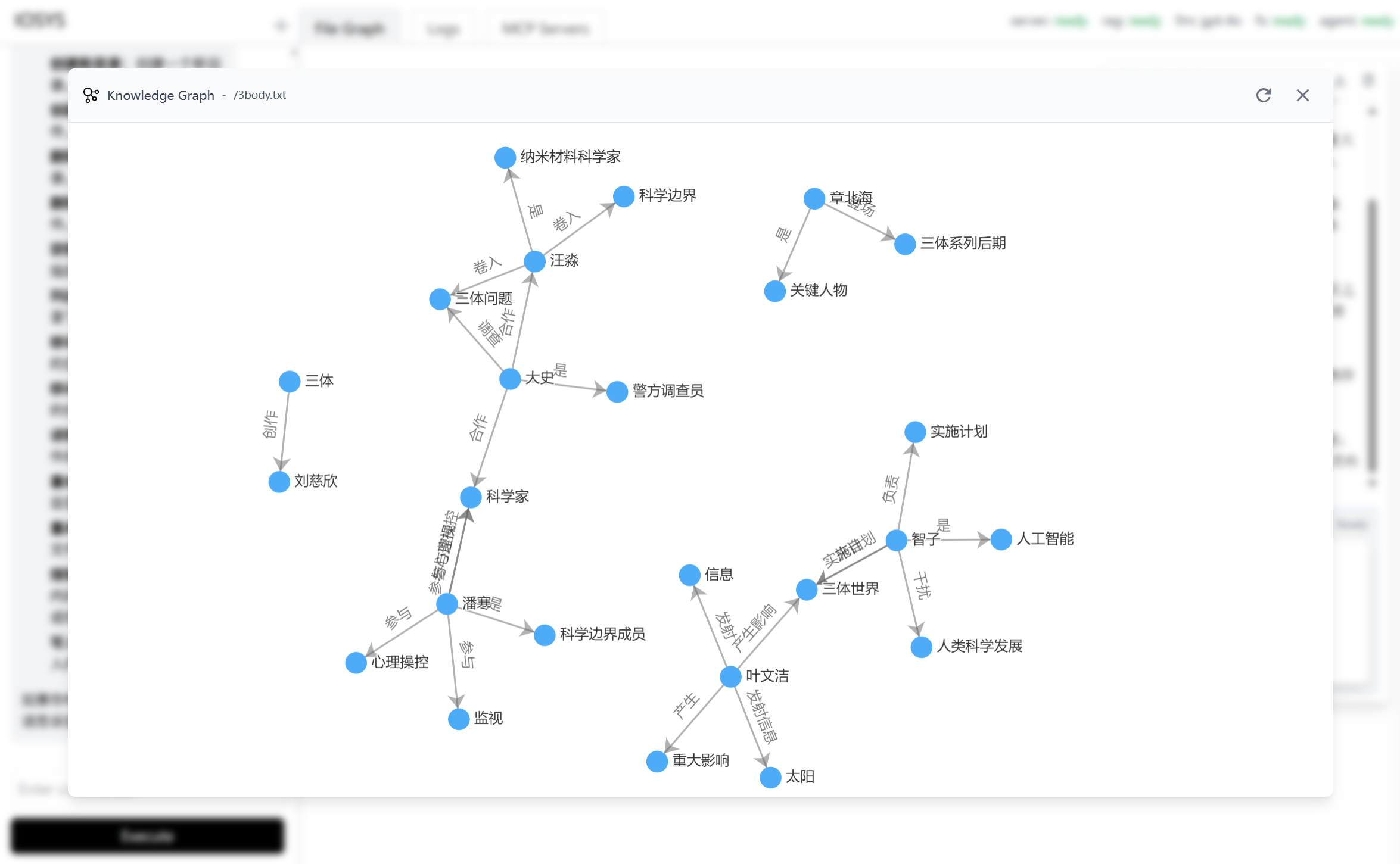
目标: 从文件文本中提取 “主-谓-宾” 三元组,构建结构化的知识网络。
工作流程: 对于小文件,直接调用 LLM 提取;对于大文件,先使用
Jieba进行分块,再分批处理。提取出的三元组经过标准化、过滤和去重后,存入知识图谱。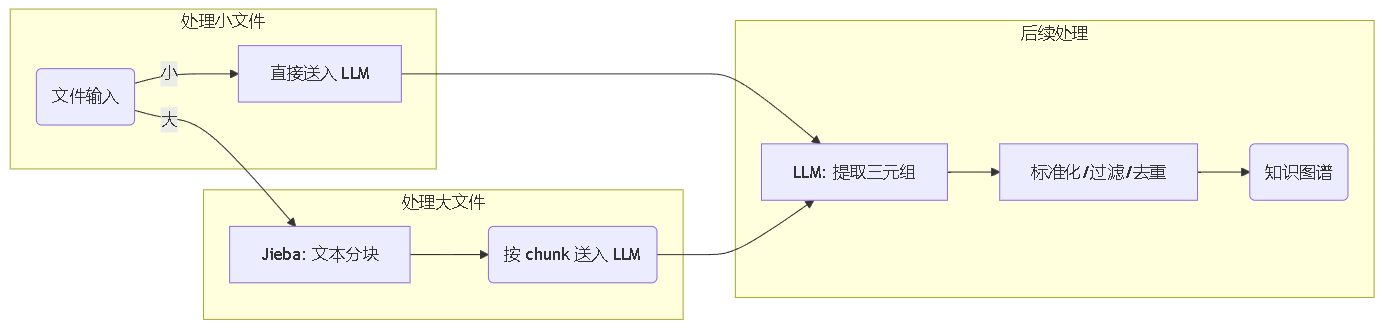
特性: 知识图谱支持按需生成、持久化存储以及将目录下多个文件的图谱合并展示,使用户能宏观地洞察文件集合内的知识关联。下图为《三体》人物关系图谱的生成示例。
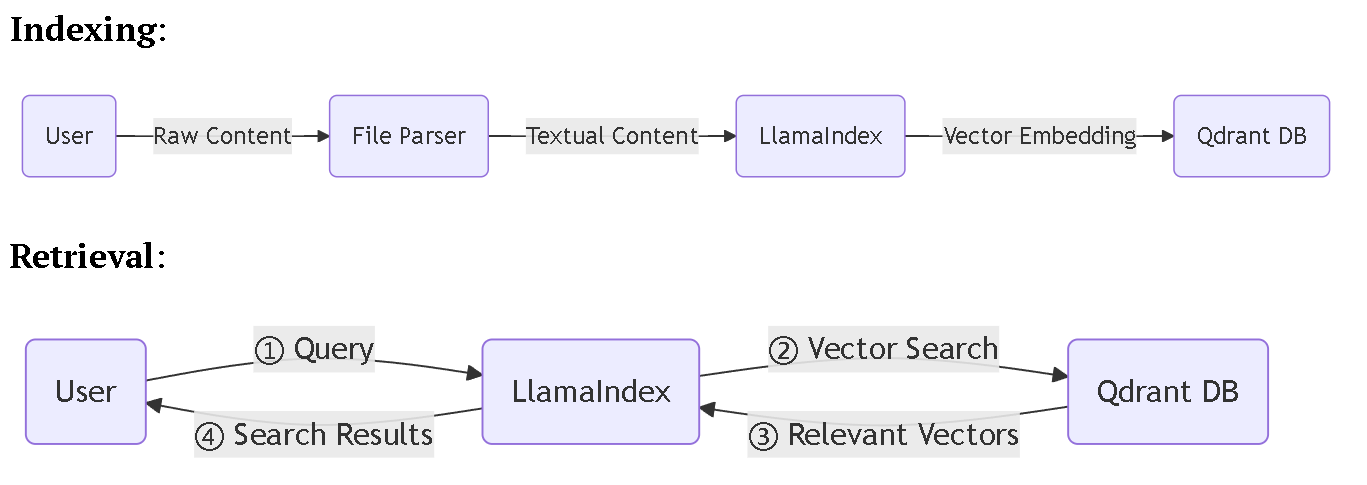
向量索引 (Vector Indexing) 与检索功能:
架构:
- 索引: 文件经由 File Parser 文本化后,送入 LlamaIndex 框架,生成向量嵌入(Vector Embedding),并存入 Qdrant 向量数据库。
- 检索: 用户查询通过 LlamaIndex 在 Qdrant 中进行向量相似度搜索,召回最相关的文本片段,作为上下文提供给 LLM 生成最终答案。我们使用了 openai 提供的
text-embedding-ada-002模型进行 "embedding", 进而实现文件的语义检索功能.
技术选型: 我们调研并实践了 GraphRAG、RAGFlow 等方案,最终因其成熟的生态和友好的 API 而选择了 LlamaIndex。所以理论上该部分的性能仍有进一步调优的空间。
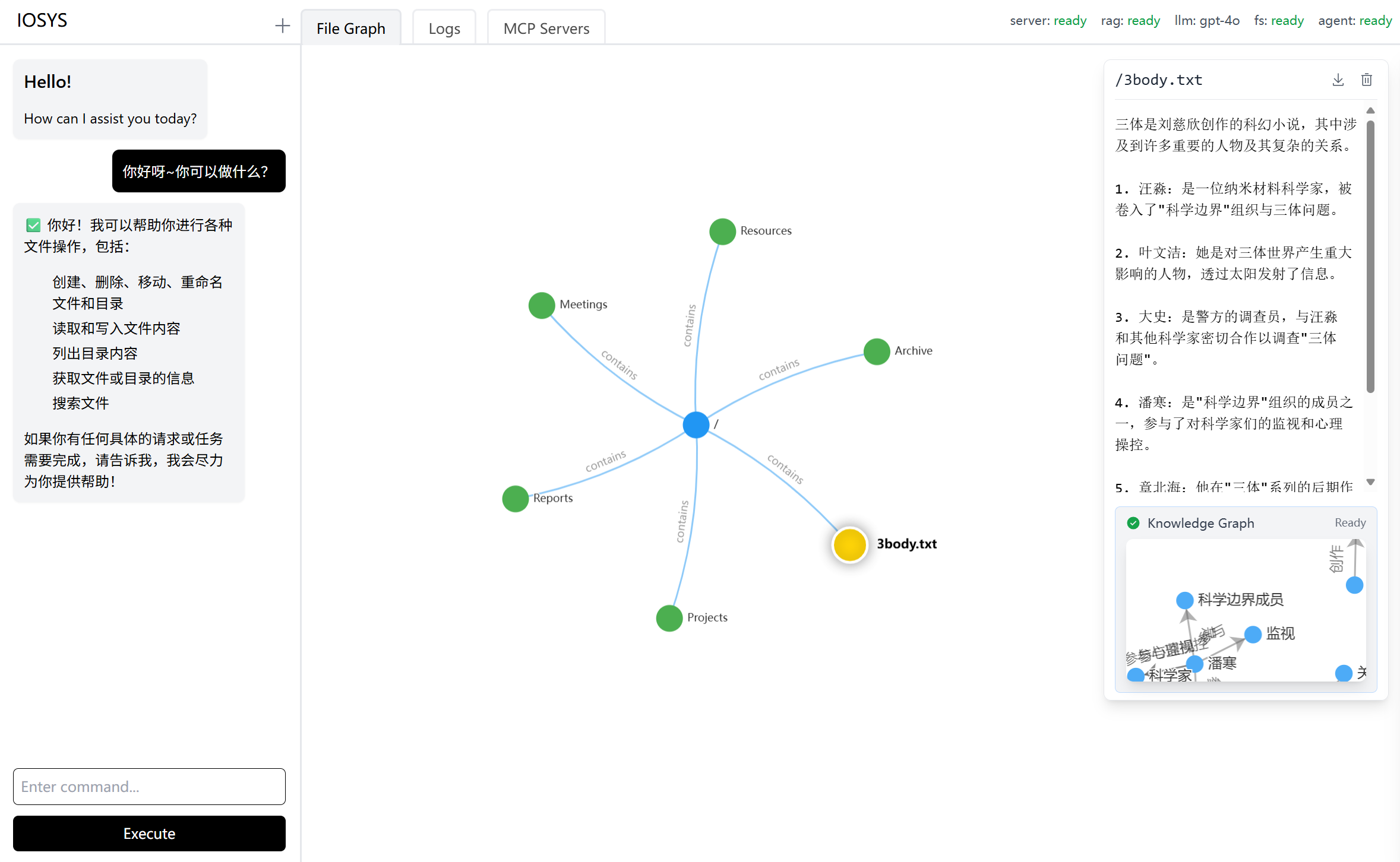
2.2.5. Web UI 模块
Web UI 是用户与 IOSYS 系统交互的主要前端界面。
设计理念:
- 支持直接操作: 在许多场景下,图形化界面的直接操作比通过 Agent 发出指令更高效, 所以我们设计了的 Web UI 也允许用户直接对文件进行增删等操作。
- 直观: 以图的形式直观展示文件及其关联关系。
- 美观: 采用 Vercel 的 Geist 设计风格,追求简洁现代的美学。
技术栈: 使用了
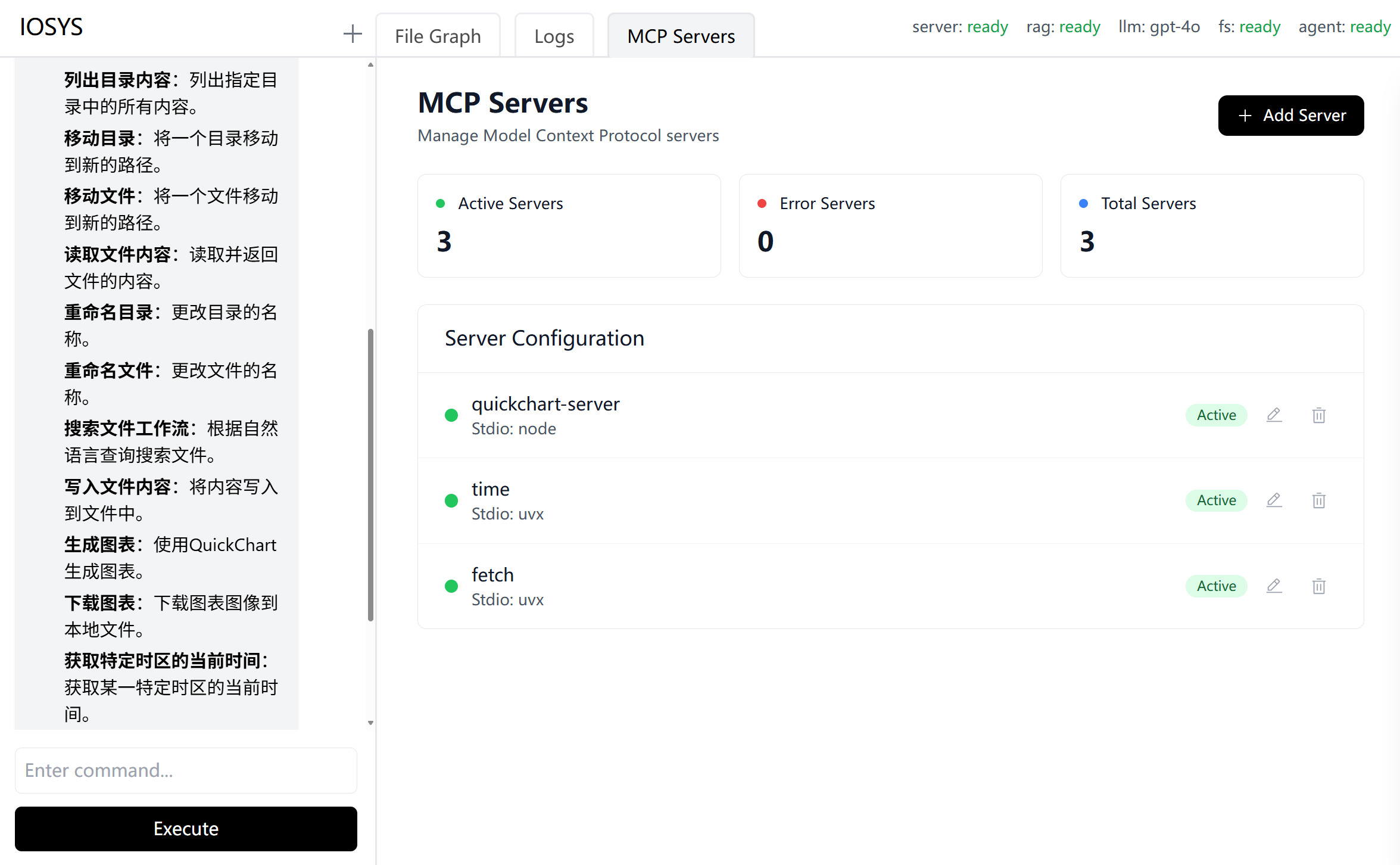
Vue、Vite、TypeScript、UnoCSS和VueUse等现代化前端技术栈。功能: 提供了文件预览、日志列表、以及可视化的 MCP 工具配置等功能。
2.2.6. A2A Server 模块
此模块是为实现 Agent 间通信而设计的独立服务器。它负责接收来自其他 Agent 的自然语言请求,并根据自身的描述和能力进行响应。我们通过 Python 代码定义了 Agent 的自我描述、能力标签和交互示例,这使其具备了被其他 Agent 发现和调用的潜力,我们认为这是项目未来最具价值的探索方向之一。
3. 项目管理与开发实践
技术栈:
- 后端: Python
- 前端: Vue, TypeScript
- 构建/包管理: uv, PNPM, Vite
开发流程:
- 模块化设计: 遵循七大模块的划分进行开发。
- 代码规范: 采用 Conventional Commits 标准提交代码(格式:
feat(module): desc)。 - 持续集成 (CI): 利用 Ruff 工具进行代码格式化和 Linting 的自动化检查与修复。
项目规模:
- 代码行数: Python (6512+), Vue (1895+), TypeScript (437+)。
- 提交次数: 540+ 次。
团队分工:
姓名 负责模块 其他工作 熊桐睿 Web UI 项目统筹,模块协调与集成 张海川 File System 云存储服务配置 朱雨田 Knowledge Graph RAG 领域的大量调研与实践 许逸凡 A2A Server LLM API Token 购置 冉竣宇 File Agent 大量调试与 Bug 修复 徐铭凯 File Parser 测试数据的制备 (全组) Backend -
4. 总结与展望
4.1. 项目总结
在一个学期的时间里,我们从一个被否决的初始构想(Nova)转型,在探索中逐步明确了方向。通过一步步绘制和完善系统架构图,团队成员找到了各自的定位,并最终通过密集的协同调试,构建出了 IOSYS 系统的原型。
与前期调研报告、可行性报告以及期中报告中提出的目标相比,我们完整实现了每一个原定的功能模块,并在此基础上设计了更为解耦, 易于二次开发的架构。
我们承认,当前系统在鲁棒性方面仍有待加强。但通过整个开发过程,我们不仅实现了一个功能丰富的智能文件 Agent,更重要的是,我们在系统架构设计、前沿 AI 技术应用(知识图谱、Tool Call、A2A)以及团队协作方面积累了宝贵的经验。
4.2. 未来展望
IOSYS 项目不仅是一个课程项目,它更像是一个探索 AIOS 可能形态的实验平台。我们认为,其最大的潜在价值在于A2A Server所代表的开放性和可扩展性。未来,当大量功能各异的 Agent 出现时,一个能够让它们通过自然语言相互发现、协同工作的协议将至关重要。IOSYS 在这方面迈出了第一步,为构建一个更加智能和互联的软件生态系统描绘了激动人心的可能性。